성능테스트에 앞서 미리 알고 있으면 좋은 것들에 대해서 설명하겠다.
성능 테스트에서 서비스가 빠른지 느린지에 대한 기준은 다음과 같이 크게 2가지로 판단할 수 있다.
- Throughput
- Latency
Throughput
Throughput이란 시간당 처리량을 의미한다.
TPS(Transaction Per Second), RPS(Request Per Second) 등으로도 불리며, '1초에 처리하는 단위 작업의 수' 혹은 '1초에 처리하는 HTTP 요청 수' 등으로 해석할 수 있다.
즉, 1초에 최대한 많은 작업을 처리할 수 있는 서비스가 성능 측면에서 좋은 서비스라고 볼 수 있다.
예를 들어, A 서비스는 1초에 1000개의 작업을 처리하고, B 서비스는 1초에 2000개의 작업을 처리할 수 있는 능력을 가졌다면 B 서비스가 동일 시간 내에 더 많은 작업을 할 수 있으므로 성능면에서 더 좋다는 것이다.
이렇듯 Throughput을 보면 내 서비스의 작업 처리 능력을 알 수 있으며, 이는 서비스 성능의 지표가 된다.
Latency
서비스의 성능을 말할 때, Latency는 서버가 클라이언트로부터 요청을 받아서 응답을 보내주기까지 걸리는 시간을 의미합니다.
쉽게 말해서 Latency는 서비스가 작업을 얼마나 빠르게 처리할 수 있는지를 나타내는 성능 지표로 볼 수 있다.
예를 들어, A 서비스의 웹 서버가 WAS로부터 요청에 대한 응답을 받는데 걸리는 시간이 100㎳이고, B 서비스의 WAS가 동일 작업을 처리하는데 50㎳가 걸렸다면 B 서비스가 작업을 더 빨리 처리할 수 있음을 알 수 있고, 이에 따라 성능면에서 더 좋다고 볼 수 있다.
이제부터는 만들었던 API에 대한 성능 테스트를 진행하겠다.
사실 여기부터가 진짜 개발자의 영역이라고 나는 생각한다.
개발자란 단순히 기능을 개발하는 것이 아니라, 문제가 발생했을 때 어떻게 빠르고 정확하게 해결하느냐의 엔지니어의 영역까지 다뤄야 된다고 생각하기 때문이다.
성능 테스트를 위해 여러가지 도구들이 많다. Jmeter, nGrinder, K6 등 많은 도구들이 있다. 그중에 필자는 Locust 를 사용하여 부하 테스트를 해보려고 한다.
Locust는 Python 기반의 오픈 소스 부하 테스트 도구로, 사용자 친화적인 웹 인터페이스를 제공하여 실시간으로 웹사이트나 API 서버의 성능을 측정하고 분석할 수 있다.
설치와 사용이 간편하며, 로컬 환경에서 빠르게 구동 가능하고, GitHub과 같은 원격 저장소를 통해 팀원들과 테스트 스크립트를 공유하며 협업할 수 있습니다.
- locustfile-issueV1
# load-test/locustfile-issueV1.py
import random
from locust import task, FastHttpUser, stats
stats.PERCENTILES_TO_CHART = [0.95, 0.99]
class CouponIssueV1(FastHttpUser):
connection_timeout = 10.0
network_timeout = 10.0
@task
def issue(self):
payload = {
"userId": random.randint(1, 10000000),
"couponId": 1
}
with self.rest("POST", "/v1/issue", json=payload):
pass- docker-compose.yml
version: '3.7'
services:
master:
image: locustio/locust
ports:
- "8089:8080"
volumes:
- ./:/mnt/locust
command: -f /mnt/locust/locustfile-issueV1.py --master -H http://host.docker.internal:8081
worker:
image: locustio/locust
volumes:
- ./:/mnt/locust
command: -f /mnt/locust/locustfile-issueV1.py --worker --master-host master
# docker-compose up -d --scale worker=3
간단하게 테스트 스크립트를 작성해보았다. 한번 docker-compose.yaml 파일을 통해 컨테이너 생성을 해보자.
$ docker-compose up -d --scale worker=3
--scale worker=3 통해 부하를 주는 워커를 3명으로 늘려주었다.
그럼 localhost:8089 를 통해서 Locust 대시보드 화면을 볼 수 있다.

간단하게 위의 항목들을 설명해 보면
- Number of users
- 최대 유저 수
- Spawn rate
- 한번에 생성되는 유저 수
- Host
- 부하 테스트를 할 호스트 주소
우리는 다음과 같은 세팅값으로 부하 테스트를 진행해 보겠다.

결과는 다음과 같다.
기본적으로 Locust에서 제공하는 차트이다.

첫번째 그래프의 Total Requests per Second를 보시면 최대 RPS가 2000 가까이 되는 것을 볼 수 있다.
이 의미는 우리 API가 최대 1초당 2000번의 요청을 처리할 수 있다는 것을 의미한다.
두번째 그래프인 Respose Times 를 보면 최대 2700ms 이 걸리고, 최소 570ms 걸리는 것처럼 보인다.
여기서 RPS가 앞서 말한 Throughput 이라고 생각하면 되고, Response Times는 Latancy 라고 생각하면 된다. 즉 RPS 가 높을수록, Response Time 이 낮을수록 좋은 서비스라고 할 수 있다.
초당 2000 RPS를 처리 한다면 좋은 서비스가 아니냐라고 할 수 있지만, 그만큼 그래프를 보면 Latancy 도 높기 때문에 응답 속도가 느려 좋은 서비스로 보기가 어렵다.
거기다 mysql 앱이 받는 부하를 보면

거의 CPU를 70% 정도까지 쓰는 것을 볼 수 있다. DB에 부하가 지속되면 DB가 다운 될 수도 있다.
그럼 어떻게 이 문제를 해결할까?
이를 파악하기 위해서는 어디서 병목점이 생기는지를 잘 파악해야 한다.
다음을 통해서 같이 살펴보자.
병목점
애플리케이션에 부하가 생길때는 어느 부분에서 부하가 집중되는지 파악하는 것이 중요하다.
도커를 사용하는 경우 docker desktop을 통해 위처럼 실시간 처리량을 확인 가능하다.
만약 명령어를 통해 각 컨테이너의 cpu, 메모리 사용률을 알고 싶다면 다음을 참고하자.
$ docker stats
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
e8767aa9780d pricecompareredis-redis-sentinel-3 0.57% 3.129MiB / 7.668GiB 0.04% 182MB / 86.5MB 8.19kB / 184kB 5
ae5c0870acb6 pricecompareredis-redis-sentinel-2 1.14% 3.141MiB / 7.668GiB 0.04% 182MB / 86.4MB 4.1kB / 184kB 5
2f7922cb29cc pricecompareredis-redis-sentinel-1 0.91% 3.094MiB / 7.668GiB 0.04% 182MB / 86.5MB 0B / 184kB 5
97ffef08bd0f pricecompareredis-redis-slave-1-1 0.62% 9.891MiB / 7.668GiB 0.13% 73.7MB / 172MB 1.26MB / 918kB 9
85f7143104a9 pricecompareredis-redis-slave-2-1 0.74% 4.945MiB / 7.668GiB 0.06% 73.2MB / 171MB 4.1kB / 918kB 7
2f4a2302e68c pricecompareredis-redis-1 0.48% 4.812MiB / 7.668GiB 0.06% 68.6MB / 158MB 0B / 791kB 6
6d4bf130fa5d prometheus 2.75% 49.89MiB / 7.668GiB 0.64% 1.64MB / 1.64MB 60.5MB / 0B 10
6f808f7393f5 grafana 0.64% 87.09MiB / 7.668GiB 1.11% 910kB / 238kB 118MB / 0B 18
394b98a5fd96 wine-db 0.01% 137.4MiB / 7.668GiB 1.75% 2.44kB / 0B 112MB / 8.19kB 8
만약 쿠버네티스 환경이라면 다음 명령어로 파드의 상태를 확인 가능하다.
- node 사용량
$ kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
cnd2-k8s-master-1 1230m 30% 8481Mi 71%
cnd2-k8s-master-2 181m 4% 8278Mi 69%
cnd2-k8s-master-3 193m 4% 7432Mi 62%
cnd2-k8s-worker-1 850m 10% 13642Mi 85%
cnd2-k8s-worker-2 265m 3% 11617Mi 73%
cnd2-k8s-worker-3 467m 5% 9272Mi 58%
cnd2-k8s-worker-4 272m 3% 11249Mi 70%
cnd2-k8s-worker-5 342m 4% 11129Mi 70%- pod 사용량
$ kubectl top node
NAME CPU(cores) MEMORY(bytes)
details-v1-5f4d584748-2pp9x 4m 90Mi
loki-0 12m 143Mi
nfs-pod-provisioner-bd6446bd4-8bvzl 4m 8Mi
productpage-v1-564d4686f-24s9q 9m 147Mi
ratings-v1-686ccfb5d8-hqpwd 5m 88Mi
reviews-v1-86896b7648-kgh8m 5m 295Mi
reviews-v2-b7dcd98fb-r9tpw 6m 280Mi
reviews-v3-5c5cc7b6d-tbsj4 5m 303Mi
test 5m 71Mi
test222 4m 75Mi이런식으로 지금 각 파드별, 노드별, 컨테이너별로 메모리 cpu 사용량을 확인해 볼 수 있다.
그럼 일반적인 API 요청에 따른 응답 과정을 살펴보자.

만약 여기서 사용자의 트래픽이 늘어난다면 API Server 를 스케일 아웃해서 트래픽을 분산시킬수도 있을 것이다.

API Server를 늘린다고 처리량이 마냥 늘어날까에 대해서는 한번 고민해보아야 한다.
다음 경우들을 생각해보자.
Case1) Application Server에 병목 발생
- API 서버확장으로 부하를 해소할 수 있는 경우
- → API 서버 수평 확장(scale out)
- 연산이 복잡해서 CPU 사용량이 늘어난 경우
- 단순히 요청 횟수가 늘어서 CPU나 메모리가 늘어난 경우

Case2) Database Server에 병목 발생
- API 서버 확장으로 부하를 해소할 수 없는 경우
- → 캐시, Database 서버 확장(master, slave), 샤딩 등
- 이런 경우 API 서버를 수평 확장시킨다고 문제가 해결되지 않음
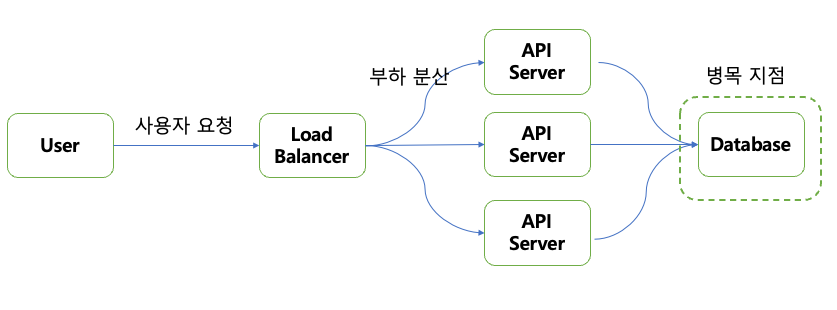
일반적으로 API Server를 확장하는 것이 Database Server를 확장하는 것 보다 관리하는 것이 더 편하다.(AWS, GCP 등 대부분의 퍼블릭 클라우드에서는 auto scaling 서비스를 지원하기 때문에)
결국, 우리는 Database 서버의 병목 지점을 해결해야 관리 포인트도 줄어들고, 운영하기가 편해진다.
사실, 병목 문제 말고도 한가지 더 크리티컬한 문제가 있다.
바로 동시성 문제이다.
우리가 생각했을 때 쿠폰 발급 갯수를 500개로 세팅을 해뒀으면 쿠폰 발급 이슈에도 500건의 데이터가 있어야 할거라 생각한다.

그런데 막상 coupon_issues 테이블을 보면 훨씬 많은 데이터가 적재되어 있다.


왜 우리가 예상한 것보다 많은 쿠폰이 발급 되었을까?
쿠폰 발급 동시성 문제
다음 경우를 한번 생각해보자.
Case1) 쿠폰 발급 요청이 순차적으로 발생하는 경우
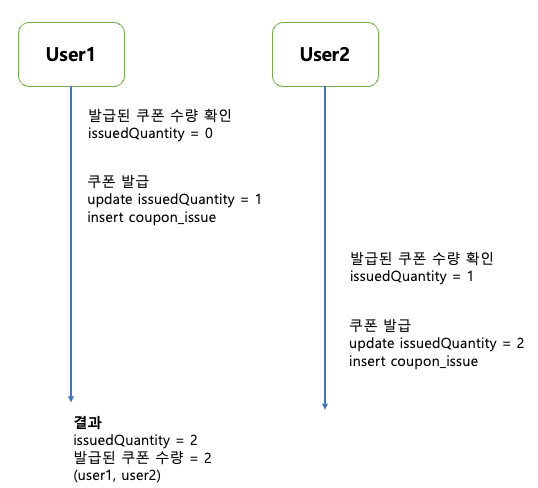
Case2) 쿠폰 발급 요청이 동시에 발생되는 경우

이런 문제를 해결하기 위해 간단한 방법은 트랜잭션이 진행될 때 LOCK 을 걸어두는 것이다.
쿠폰 발급 요청이 동시에 발생되는 경우 (LOCK)

LOCK을 적용한다는 의미
공유 자원을 동시에 접근해서 문제가 될 수 있는 부분(critical section)을 순차 처리한다.
LOCK을 통해 순차처리는 보장되지만, 처리량의 병목이 발생한다!!
- a → b → c 순차 처리 ↔ a, b, c 병렬 처리
그럼 문제점을 다 파악했으니, Mysql 기반 선착순 쿠폰 발급 기능 개발 (5)에서 위의 문제점을 어떻게 해결할 수 있는지 진행해 보겠다.
참조
'토이프로젝트 > 선착순 이벤트 쿠폰 시스템' 카테고리의 다른 글
| Mysql 기반 선착순 쿠폰 발급 기능 개발 (5) (0) | 2024.05.23 |
|---|---|
| Mysql 기반 선착순 쿠폰 발급 기능 개발 (3) (0) | 2024.04.18 |
| Mysql 기반 선착순 쿠폰 발급 기능 개발 (2) (0) | 2024.04.16 |
| Mysql 기반 선착순 쿠폰 발급 기능 개발 (1) (0) | 2024.04.08 |
| 2. 프로젝트 환경 설정 (0) | 2024.04.06 |